Predicting Players Score
30 Apr 2021 - Eloy Chang
I wanted to improve my transfer suggestion system shown in a previous post, this time using some machine learning algorithm, this means, create a function that, given some players variables (like previous goals scored for example) it returns the points the player would obtain in the next gameweek.
This process include:
- Create the variables to use in the model.
- Clean and make some feature engineering.
- Train the model and tune hyper params.
- Validate the results.
Train and test methodology
When this was written, the gameweek 31 of the 20/21 season had just ended, in this case the dataset will be divided in 3:
- All data from gameweek 1 to 29: This data will produce the predictors.
- Gameweek 30 data: This will be the target data to train and validate.
- Gameweek 31 data: This will be the testing data once all the algorithms, hyper params and feature engineering operations are selected.
The variables
A total of 50 variabler were created, separated in 6 categories:
- Raw last fixture stats (12 variables).
- Aggregate fixtures stats of last 3 matches (12 variables).
- Aggregate fixtures stats of the season (12 variables).
- Home/away club winning rate / points gather (4 variables).
- Fixture difficulty winning rate / points gather (8 variables).
- Player form and chance of playing next round (2 variables).
The fixture stats calculated were:
- Total points.
- Transfers in.
- Transfers out.
- Minutes.
- Goals scored.
- Assists.
- Goals conceded.
- Own goals.
- Yellow cards.
- Red cards.
- Saves.
- Bonus.
In the case of the aggregations of the last 3 matches and the season the sum of all gameweeks involved was used.
Feature engineering
Before training the features (variables) were explored to find some irregularities or interesting insights. The first thing was look for missing values, as we expected, the info for all player that do not played the last gameweek do not have info of it (variables with the lm_ prefix), but also are some player that do not had have played games at home or away (very few of it) or of some difficult, being the higher difficult the most common to find this players.
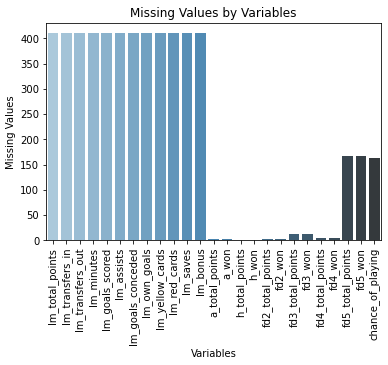
Given that the variables are sums of events made by the players, substituting the missing values by 0 seems to be a good idea.
Another important thing to look at is the distribution of the target variable,but it is likely to concentrate all values in 0, because most of the players in the database do not play, they are 687 total players, but only 20 teams, and just 11 player of each team start the games with a maximum of 3 changes, this means 14 player of each play, 14 players * 20 teams are 280 players are the normal quantity of players that may have points, but inclusive if a player has some minutos it can even have 0 points, by the other side, the most common total point gained by all players by gameweek is 1 and 2 points.
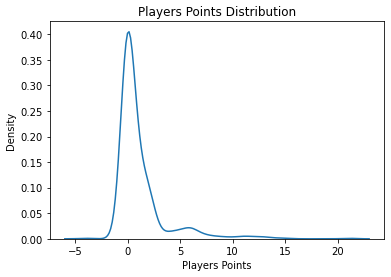
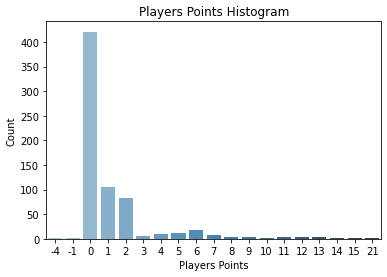
This may affect the model performance because what we really want to predict is which players will obtain more points, so, to force the model to take more into account this players we duplicate all players that have points.
Finally to reduce the number of features a dimension reductión algorithm was made (PCA in this case), his algorithm reduce the number of features to just 6, and those capture 99,96% of the variance of the dataset, this means, this 6 new features describe the complete dataset at 99,96%, even more, this new features have some nice properties (orthogonality as and example) that improve the models training performance.
Training
The algorithm selected was a random forest, and the metric used to test was the MSE (mean squared error) but with a modification, given that most of players has 0 points, the MSE were divided between players with points and players without points, then a weighted mean have been calculated given 60% of weight to players with score and 40% to players without it.
To tune the hyper params I develop a ´modeler´ object, which uses random search of the selected params and returns the best combination of them. Random search is no more that given some params and a range of values where we want to test the params, the algorithm chose a random value for each param and train the model, then chose another values and so on multiple times, them return the params selection with the best value of the chosen metric to evaluate the model.
The final model has a MSE of 0.276.
Validation
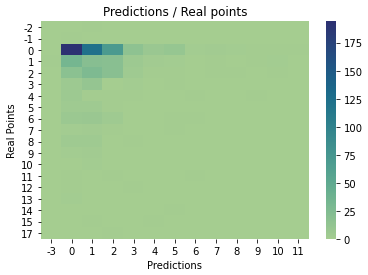
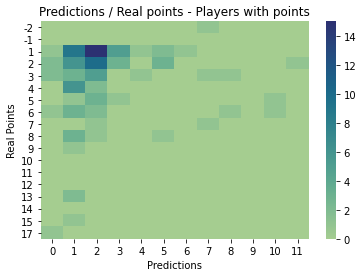
Finally I compare the results of the model with the actual gameweek, the model actually predict the exact points of 337 players which is 48% of the players, which is not bad, but, of this only 79 players actually really played, this mean that the model just predict the exact points of 29% of the players with points.
In general the weighted MSE in the test gameweek was of 0.15 points which is a good value taking into account the range of values of the target..
The things to improve is that the model is not too accurate with the players that scored a lot of points which are, actually, the players that really matter to add this model to my suggested players transfers module, still, it had some good performances.